|
 |
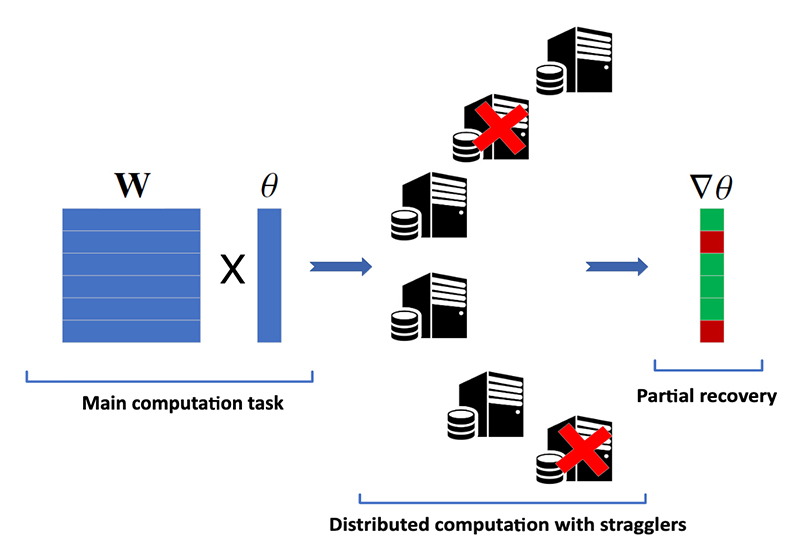
Fig. 1 from the paper: Illustration of partial recovery in a naive distributed computation scenario with six "worker" machines, two of which are stragglers. |
|
One of the main factors behind the success of machine learning algorithms is the availability of large datasets for training. However, as datasets become ever larger, the required computation becomes impossible to execute in a single machine within a reasonable time frame. This computational bottleneck can be overcome by distributed learning across multiple machines, which are typically called “workers.”
Gradient descent (GD) is the most common approach in supervised learning, and can be easily distributed. By employing a parameter server (PS) type framework, the dataset can be divided among workers, and at each iteration, workers compute gradients based on their local data, which can be aggregated by the PS. However, slow and so-called “straggling” worker machines are the Achilles heel of distributed GD since the PS has to wait for all the workers to complete an iteration.
A wide range of straggler-mitigation strategies have been proposed in recent years. The main notion is to introduce redundancy in the computations assigned to each worker, so that fast workers can compensate for the stragglers.
A new approach to the problem appears in the paper Age-Based Coded Computation for Bias Reduction in Distributed Learning by Reader in Information Theory and Communications Deniz Gunduz, Department of Electrical and Electronic Engineering, Imperial College London; his Ph.D. student Emre Ozfatura; Professor Sennur Ulukus (ECE/ISR); and her Ph.D. student Baturalp Buyukates.
Existing solutions
Most “coded computation” solutions for straggler mitigation suffers from two drawbacks: First, they allow each worker to send a single message per iteration, which results in the under-utilization of computational resources. Second, they recover the full gradient at each iteration, which may unnecessarily increase the average completion time of an iteration.
Multi-message communication (MMC) strategy addresses the ?rst drawback by allowing each worker to send multiple messages per-iteration, thus, seeking a balance between computation and communication latency. The second drawback can be addressed by combining coded computation with partial recovery (CCPR) to provide a trade-off between the average completion time of an iteration and the accuracy of the recovered gradient estimate.
If the straggling behavior is not independent and identically distributed over time and workers—often the case in practice—the gradient estimates recovered by the CCPR scheme become biased. This may happen when a worker machine straggles over multiple iterations. Regulating the recovery frequency of the partial computations to make sure that each partial computation contributes to the model updates as equally as possible is critical to avoid biased updates.
The new paper’s solution
In the new paper, the authors use the age of information (AoI) metric to track the recovery frequency of partial computations.
AoI has been proposed to quantify data freshness over systems that involve time-sensitive information. AoI studies aim to guarantee timely delivery of time-critical information to receivers. AoI has found applications in queueing and networks, scheduling and optimization, and reinforcement learning. In the new paper, the authors associate an age to each partial computation and use this age to track the time passed since the last time each partial computation has been recovered.
The researchers design a dynamic encoding framework for the CCPR scheme that includes a timely dynamic order operator that prevents biased updates and improves performance. This scheme increases the timeliness of the recovered partial computations by changing the codewords and their computation order over time. To regulate the recovery frequencies, the authors use age of the partial computations in the design of the dynamic order operator. They show by numerical experiments on a linear regression problem that the proposed dynamic encoding scheme increases the timeliness of the recovered computations, results in less biased model updates, and as a result, achieves better convergence performance compared to the conventional static encoding framework.
Although the paper’s main focus is on coded computation, the advantages of the timely dynamic encoding strategy are not limited to the coded computation scenario. The same strategy also can be used for coded communication and uncoded computation scenarios.
Related Articles:
'OysterNet' + underwater robots will aid in accurate oyster count
Manocha Receives 2022 Verisk AI Faculty Research Award
Exploring the 'rules of life' of natural neuronal networks could lead to faster, more efficient computers
Fermüller, ARC Lab create app to improve violin instruction
Making AI safe with independent audits
How tech can fill gaps in mental health care
Manocha talks AI on Federal News Network podcast
A new way to monitor mental health conditions
ISR faculty leading, playing key roles in ARL cooperative agreement
Computational framework automatically optimizes the shape of tissue engineered vascular grafts
June 17, 2020
|
